YOLO (You Only Look Once)
YOLO 란?
YOLO(You Only Look Once)는 1-stage detector로 분류되며 R-CNN 계열의 2-stage detector와 달리 Classification, Bounding box regression이 한번에 처리 됩니다. 2-stage detector 보다 처리 속도가 빨라서 Real time object detection 분야에 사용되는 알고리즘 입니다.

YOLO는 이미지 내의 Bounding box와 Class probability를 Single regression problem으로 처리하며, 이미지를 한번 보는(You Only Look Once) 것으로 Object의 Class와 Location을 detection 합니다.

위의 그림의 설명은 다음과 같습니다.
- 입력 이미지를 448x448로 리사이즈 합니다.
- Single convolutional network에 이미지를 통과 시킵니다.
- 모델의 신뢰도에 따라 결과로 나오는 Detection들을 임계화(Threshold) 시킵니다.
한마디로 입력 이미지를 Single CNN에 통과시켜 Multiple bounding box에 대한 Class probablility를 계산한다는 뜻입니다.
YOLO, YOLOv2, YOLOv3, YOLOv4, YOLOv5 까지 모델이 개발 되었고 각 모델마다 장단점이 존재 합니다.
예를 들어 YOLOv3는 Object detection 성능은 좋지만 Yolov2에 비해서 느리다는 단점이 있습니다.
1. Bounding box 찾는 방식
Bounding box를 찾는 방법은 크게 2가지로 나눌 수 있습니다. Proposal 방식과 Grid 방식입니다.
1) Proposal 방식

Proposal 방식의 대표적인 예는 Selective search 알고리즘과 Faster R-CNN의 RPN(Region Proposal Network)가 있습니다. Proposal 방은 정확도가 높지만 Proposal bouding box의 수가 많아서 오버헤드가 크기 때문에 속도가 느립니다.
2) Grid 방식

반면 Grid 방식은 Grid cell의 갯수가 Proposal 수로 Proposal을 구하는 과정에서 연산이 거의 필요하지 않습니다. 물론 Grid cell의 Object가 있다는 보장은 없으나 이는 Proposal방식도 마찬가지 입니다. 따라서 Proposal방식에 비해서 Bounding box 찾는 속도가 매우 빠릅니다.
2. Unified Detection

R-CNN계열의 2-stage detector는 [Region proposal] -> [Classification, Bounding box regression] 이렇게 2단계로 나누어서 동작하는 방식인데 반해 YOLO는 Region prosal을 제거한 1-Stage 방식으로 동작합니다.
위의 그림에서 S x S grid on input의 이미지가 YOLO Network에 통과하면 그림 중앙의 [Bounding boxes + confidence]와 [Class probability map]을 얻습니다. Final detections은 최종 결과 물입니다.
YOLO 동작하는 순서를 좀더 구체적으로 설명하면 다음과 같습니다.
- 입력 이미지를 SxS 그리드(Grid) 영역으로 분할 합니다.
- 각각의 그리드 셀(Cell) 은 물체가 있을 만한 영역에 해당하는 B개의 Bounding box를 예측합니다.(x,y와 w,h로 나누지는데 x, y는 bounding box의 중심 좌표이며, w, h는 넓이와 높이 입니다.)
- 각 Bounding box에 대한 Confidence score를 계산합니다. Confidence score 해당 그리드에 물체가 있을 확률 Pr(Objectd)와 예측한 박스의 Ground Truth 박스와의 IoU(Intersection over Union)을 곱해서 계산합니다.
- 각각의 그리드 마다 C개의 클래스에 대한 클래스의 확률을 계산합니다. 기존의 Object detection 모델과는 다른점은 클래스 갯수 + 1(배경)을 넣어서 Classification을 하는데 YOLO는 그럴 필요가 없습니다.
- Confidence score: Pr(Object) X IoU_truth_pred
- Conditational Class Probability: Pr(Class_i|Object)
3. Network Design

YOLO의 CNN Architecture는 GoogLeNet 모델을 기반으로 합니다. 대신 Inception 블럭 대신 단순한 Convoltuion으로 네트워크로 구성했다는 점이 다릅니다.
224x224 크기의 Image Net으로 Pretrain 시켰습니다. 실제 입력 이미지로는 448x448 크기 이미지를 받습니다.
그리고 앞쪽 20개의 Convolutional Layer는 Freeze한채, 뒷 단의 4개 Layer만 Object detection에 맞게 학습시킵니다.

Inference부분을 설명하자면 GoogLeNet를 통과한후 CNN Layer 4회, FC(Fully Connected) Layer를 2번 통과하고 최종사이즈가 7x7x30로 출력으로 만들어 집니다.
4. Inference
이미지 출처: Deep System’s YOLO

이미지가 YOLO Network를 통과하면 출력이 7x7x30로 나옵니다. 여기서 7x7은 Grid를 의미하며 30은 Vector의 차원 입니다. 위의 그림은 왼쪽의 Grid cell(빨간색으로 표시)에서 예측한 Bounding box(노란색으로 표시)를 나타내고 있습니다.
각각의 Grid cell은 B개의 Bounding box를 가지고 있습니다.
위의 그림에서 5의 뜻은 해당 Grid cell 의 첫번째 Bounding box에 대한 값이 저장 되어 있습니다.
Bounding box(노란색)는 그 중심이 빨간색의 Grid cell(빨간색)에 위치해야 하며, Width, Height는 Grid cell보다 크거나 작을 수도 있습니다.
- 이미지를 7x7의 Grid로 분할합니다
- 30개의 채널은 [Bounding box의 4개(x,y와 w,h)와 Bounding box안의 Object가 있을 Confidence] x2개로 구성되어 있습니다.
- Bounding box의 중심 좌표 x, y 입니다.
- Bounding box의 크기: w, h 입니다.

두번째 Bounding box에 대한 그림입니다. 첫번째 5개는 1번째 Bounding box에 대한 정보가 있으며 다음의 5개는 2번째 Boundiuung box에 정보를 가지고 있습니다. 첫번째와 두번째의 Bounding box의 모양과 크기는 다를수 있습니다.

그다음 나머지 20차원 Vector는 해당 인덱스가 Class의 특정 확률 값을 뜻합니다. Confidence score를 구할때 Pr(Object) X IoU_truth_pred로 계산했으며 그리고 Conditational Class Probability를 구할때 Pr(Class_i|Object)로 계산했습니다.
이둘을 곱해주면 Pr(class_i) X IoU가 되는데 해당 박스가 특정 클래스일 확률 값이 됩니다.

이러한 작업을 인덱스당 B개의 Bounding 박스에 수행하고, SxS Grid Cell에 적용하면 다음과 같은 결과를 얻습니다.

이렇게 구한 벡터들을 모두 모은 뒤 일렬로 나란히 세우면, 가장 위 차원부터 각 클래스별로 전체 바운딩 박스에서 확률 값을 구할 수 있습니다.

여기서 동일한 물체에 중복되어 지정한 박스들을 NMS(Non-maximum Suppression)을 수행하여 중복된 박스들을 제거합니다. NMS 거친후 중복을 제외한 박스(진짜 Object)들을 그려주게 됩니다.
5. Loss function

YOLO의 Loss function은 여러가지 Loss로 구성 되어 있어 복잡해 보이지만 하나씩 분석해보면 이해 가능합니다.

1) Object가 존재하는 [Grid cell의 i]와 [Predictor bounding box의 j]에 대한 x, y의 Loss를 계산합니다.

2) Object 존재하는 [Grid cell의 i]와 [Predictor bounding box의 j]에 대한 width와 height의 Loss를 계산합니다.

3) Object 존재하는 [Grid cell의 i]와 [Predictor bounding box의 j]에 대한 confidence score의 Loss를 계산합니다.

4) Object 존재하지 않는 [Grid cell의 i]와 [Predictor bounding box의 j]에 대한 confidence score의 Loss를 계산합니다.
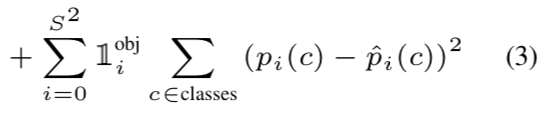
5) Object 존재하는 [Grid cell의 i]에 대해, Confidence score의 Loss를 계산합니다.
6. 결론
- 다른 Object detection 모델 보다 상대적으로 빠릅니다(YOLO 45 fps, YOLO-tiny 155fps)
- End to end로 학습이 가능합니다.
- Localization error는 더 발생하지만 Background(배경)에 대한 오인식(False positive)을 줄어 들었습니다.
- Detection 성능은 SOTA보다 떨어 집니다.(YOLO v1 당시 기준)
- Fast R-CNN + YOLO 모델을 Combine 시키면 성능이 매우 높습니다.
- Object의 General representations(일반적인 형질)을 잘 학습니다.
1) 성능
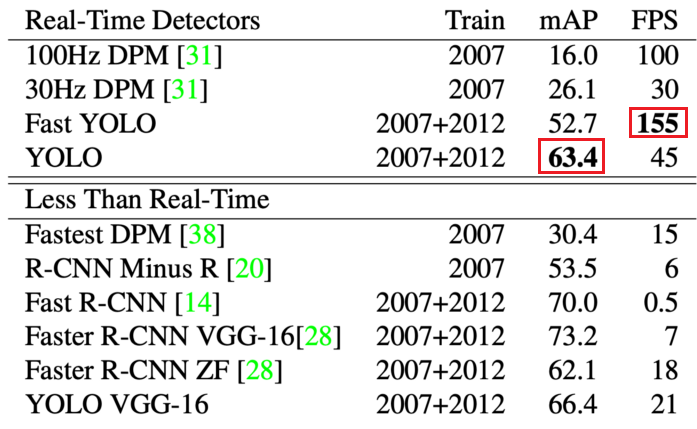
YOLO 논문에서는 객체 탐지를 수행하는 모델인 DPM, R-CNN, Fast R-CNN, Faster R-CNN과 원래의 YOLO를 설계를 간소화 해서 사용하여 정확도를 포기하고 성능을 높인 Fast YOLO 등의 모델의 mAP와 초당 프레임 수 FPS를 비교하였습니다. 위 표에서 YOLO는 63.4 mAP를 가지며 초당 45장의 이미지를 처리 할 수 있습니다. 그리고 경량 버전인 Fast YOLO는 정확도는 조금 낮지만 155 FPS의 놀라운 처리 속도를 보여줍니다. YOLO가 가장 정확도가 높은 모델은 아니지만 이 논문이 작성될 당시에는 가장 빠른 처리 속도를 가진 모델이고 영상에서도 프레임이 끊기지 않고 부드럽게 객체를 탐지할 수있습니다.
2) 장점과 단점
장점
- 간단한 처리 과정으로 속도가 매우 빠릅니다. 또한 기존의 다른 Real time detection system들과 비교할 때, 2배 정도 높은 mAP를 보여줍니다.
- Image 전체를 한번에 바라보는 방식으로 Class에 대한 맥락적 이해도가 높습니다. 이로인해 낮은 background error(False-Positive)를 보입니다.
Object에 대한 좀 더 일반화된 특징을 학습합니다. 가령 Natural image로 학습하고 이를 Artwork에 테스트 했을때, 다른 Detection System들에 비해 훨씬 높은 성능을 보여줍니다.
단점
- 작은 물체에 대해서 탐지가 잘 되지 않는다는 단점이 있습니다.
- 데이터를 입력 받은 다음 Bounding box를 학습하기 때문에 Object가 무엇인지, 그리고 이상한 비율로 되어 있는 물체라던지, 일반화된 지식이 있어야 구별할 수 있는 학습은 하지 못한다는 단점이 있습니다.